
Share This Article
1. Giới Thiệu Về Unsupervised Learning
Học không giám sát (Unsupervised Learning) là một nhánh của học máy (Machine Learning), nơi thuật toán không có nhãn đầu ra mà phải tự tìm hiểu cấu trúc dữ liệu.
Sự khác biệt giữa Unsupervised Learning và Supervised Learning:
- Supervised Learning: Có nhãn đầu ra (y) → Dự đoán cụ thể.
- Unsupervised Learning: Không có nhãn → Phát hiện mẫu, nhóm dữ liệu tương tự.
Ứng dụng thực tế của Unsupervised Learning:
- Phân cụm khách hàng (Customer Segmentation)
- Giảm chiều dữ liệu (Dimensionality Reduction)
- Phát hiện bất thường (Anomaly Detection).
2. Các Phương Pháp Chính Trong Unsupervised Learning
2.1. Phân Cụm (Clustering)
Nhóm các điểm dữ liệu có đặc điểm giống nhau vào cùng một cụm.
Ví dụ: Phân nhóm khách hàng theo hành vi mua hàng.
Thuật toán phổ biến:
- K-Means: Chia dữ liệu thành K cụm.
- Hierarchical Clustering: Xây dựng cây phân cấp để nhóm dữ liệu.
2.2. Giảm Chiều Dữ Liệu (Dimensionality Reduction)
Loại bỏ thông tin dư thừa để tối ưu mô hình.
Ví dụ: Giảm số lượng biến đầu vào khi xử lý ảnh hoặc văn bản.
Thuật toán phổ biến:
- PCA (Principal Component Analysis): Biến đổi dữ liệu thành các thành phần chính.
- t-SNE (t-Distributed Stochastic Neighbor Embedding): Trực quan hóa dữ liệu nhiều chiều.
2.3. Phát Hiện Bất Thường (Anomaly Detection)
Tìm kiếm các điểm dữ liệu bất thường hoặc lỗi trong tập dữ liệu.
Ví dụ: Phát hiện gian lận trong giao dịch tài chính.
Thuật toán phổ biến:
- Isolation Forest: Phát hiện điểm bất thường bằng cách xây dựng cây ngẫu nhiên.
- DBSCAN (Density-Based Spatial Clustering of Applications with Noise): Phát hiện nhóm dữ liệu và điểm nhiễu.
3. Hướng Dẫn Code Unsupervised Learning Bằng Python
Chúng ta sẽ thử nghiệm K-Means Clustering và PCA trên dữ liệu hoa Iris.
3.1. Cài Đặt Thư Viện Cần Thiết
|
1 |
pip install numpy pandas scikit-learn matplotlib seaborn |
3.2. Import Thư Viện Và Dữ Liệu
|
1 2 3 4 5 6 7 8 |
import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns from sklearn.datasets import load_iris from sklearn.cluster import KMeans from sklearn.decomposition import PCA from sklearn.preprocessing import StandardScaler |
3.3. Tải Và Tiền Xử Lý Dữ Liệu Iris
|
1 2 3 4 5 6 7 8 9 10 11 |
# Tải dataset Iris iris = load_iris() X = iris.data # Dữ liệu đầu vào # Chuẩn hóa dữ liệu scaler = StandardScaler() X_scaled = scaler.fit_transform(X) # Hiển thị thông tin dataset print(f"Kích thước dữ liệu: {X.shape}") print("Tên thuộc tính:", iris.feature_names) |
Giải thích:
- Dữ liệu Iris có 4 thuộc tính: chiều dài & rộng của cánh hoa và đài hoa.
- StandardScaler giúp chuẩn hóa dữ liệu về khoảng [-1, 1] để tăng hiệu suất mô hình.
4. Phân Cụm Dữ Liệu Bằng K-Means
4.1. Xây Dựng Mô Hình K-Means
|
1 2 3 4 5 6 7 8 9 10 |
# Chạy K-Means với K=3 (vì Iris có 3 loài hoa) kmeans = KMeans(n_clusters=3, random_state=42) clusters = kmeans.fit_predict(X_scaled) # Thêm kết quả phân cụm vào DataFrame df = pd.DataFrame(X, columns=iris.feature_names) df["Cluster"] = clusters # Hiển thị kết quả phân cụm print(df.head()) |
Giải thích:
- K-Means chia dữ liệu thành 3 cụm (vì Iris có 3 loại hoa).
- fit_predict() gán mỗi điểm dữ liệu vào một cụm.
4.2. Trực Quan Hóa Kết Quả K-Means
|
1 2 3 4 5 6 7 8 9 10 11 |
# Giảm chiều dữ liệu xuống 2D bằng PCA pca = PCA(n_components=2) X_pca = pca.fit_transform(X_scaled) # Vẽ biểu đồ phân cụm plt.figure(figsize=(8,5)) sns.scatterplot(x=X_pca[:, 0], y=X_pca[:, 1], hue=clusters, palette="Set2") plt.title("Phân Cụm K-Means Trên Iris (Sau PCA)") plt.xlabel("Thành phần chính 1") plt.ylabel("Thành phần chính 2") plt.show() |
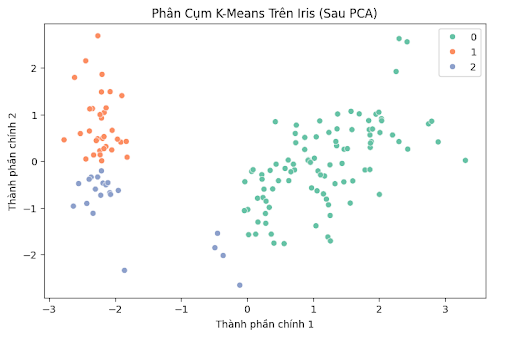
Giải thích:
- Dùng PCA giảm dữ liệu 4 chiều xuống 2 chiều để trực quan hóa.
- Hue=clusters để hiển thị cụm màu sắc khác nhau.
Bạn có thể xem Code mẫu ở đây (Google Colab)
5. Giảm Chiều Dữ Liệu Bằng PCA
5.1. Áp Dụng PCA
|
1 2 3 4 5 6 7 |
# Giảm chiều dữ liệu xuống 2 thành phần chính pca = PCA(n_components=2) X_pca = pca.fit_transform(X_scaled) # Hiển thị tỷ lệ phương sai của từng thành phần chính print(f"Tỷ lệ phương sai giữ lại: {pca.explained_variance_ratio_}") print(f"Tổng phương sai giữ lại: {sum(pca.explained_variance_ratio_):.2%}") |
Giải thích:
PCA giúp giảm số chiều từ 4 xuống 2, trong khi vẫn giữ lại phần lớn thông tin.
5.2. Trực Quan Hóa PCA
|
1 2 3 4 5 6 |
plt.figure(figsize=(8,5)) sns.scatterplot(x=X_pca[:, 0], y=X_pca[:, 1], hue=iris.target, palette="Set1") plt.title("Giảm Chiều Dữ Liệu Iris Bằng PCA") plt.xlabel("Thành phần chính 1") plt.ylabel("Thành phần chính 2") plt.show() |

PCA giúp nhận biết nhóm dữ liệu mà không cần nhãn!
6. Ưu Nhược Điểm Của Unsupervised Learning
| Ưu điểm | Nhược điểm |
| Khám phá dữ liệu mà không cần nhãn | Kết quả khó diễn giải hơn Supervised Learning |
| Tự động tìm mối quan hệ trong dữ liệu | Dễ bị ảnh hưởng bởi nhiễu |
| Hữu ích trong phân cụm & phát hiện bất thường | Không thể đánh giá mô hình bằng độ chính xác |
Cách khắc phục nhược điểm:
- Kết hợp với Supervised Learning để gán nhãn dữ liệu sau khi phân cụm.
- Dùng nhiều thuật toán khác nhau để so sánh kết quả.
7. Kết Luận
- Unsupervised Learning là một công cụ mạnh mẽ để khám phá dữ liệu và trích xuất thông tin tiềm ẩn.
- Bạn có thể thử nghiệm các thuật toán khác như DBSCAN, Isolation Forest để phát hiện bất thường!