

Share This Article
1. Giới thiệu về Học Tăng Cường ( Reinforcement Learning – RL):
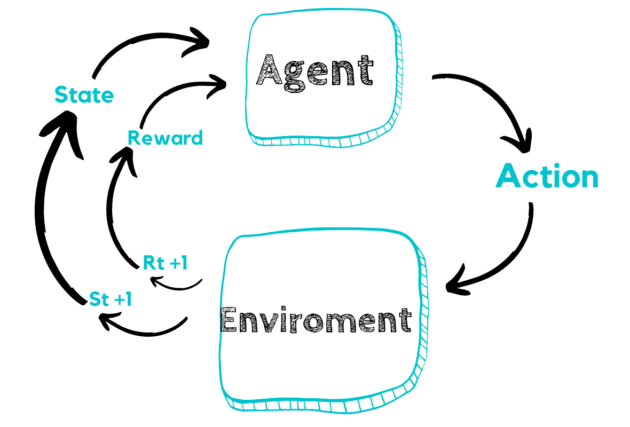
Học tăng cường (Reinforcement Learning – RL) là một nhánh của học máy (Machine Learning), trong đó một tác nhân (Agent) học cách đưa ra quyết định tối ưu bằng cách tương tác với môi trường.
Sự khác biệt giữa Reinforcement Learning và các loại học máy khác:
- Supervised Learning: Học từ dữ liệu có nhãn sẵn.
- Unsupervised Learning: Học từ dữ liệu không có nhãn.
- Reinforcement Learning: Học thông qua thử nghiệm & phản hồi từ môi trường.
Ứng dụng thực tế của Reinforcement Learning:
- AI chơi game (AlphaGo, Dota2 Bot, Chess AI)
- Ô tô tự lái (Self-driving Cars)
- Robot thông minh, tự động hóa trong công nghiệp.
2. Cách hoạt động của Reinforcement Learning
Reinforcement Learning có 4 thành phần chính:
- Agent (Tác nhân): Hệ thống AI đưa ra quyết định.
- Environment (Môi trường): Nơi tác nhân hoạt động và nhận phản hồi.
- Actions (Hành động): Các lựa chọn mà tác nhân có thể thực hiện.
- Rewards (Phần thưởng): Phản hồi từ môi trường sau mỗi hành động.
Cách RL học:
- Agent thực hiện hành động → Nhận phản hồi (Reward/Punishment) → Cập nhật chiến lược.
- Mục tiêu: Tối đa hóa tổng phần thưởng trong dài hạn.
3. Các Thuật Toán Phổ Biến Trong Reinforcement Learning
Các thuật toán chính trong RL:
- Q-Learning: Mô hình học dựa trên bảng Q-value (off-policy).
- Deep Q-Network (DQN): Dùng Deep Learning để cải thiện Q-Learning.
- Policy Gradient (REINFORCE): Trực tiếp tối ưu hóa chính sách hành động.
4. Hướng Dẫn Code Reinforcement Learning Bằng Python
Chúng ta sẽ xây dựng một mô hình Q-Learning đơn giản để huấn luyện AI chơi FrozenLake từ OpenAI Gym.
4.1. Cài Đặt Thư Viện Cần Thiết
|
1 |
pip install numpy gym |
4.2. Import Thư Viện
|
1 2 |
import numpy as np import gym |
4.3. Khởi Tạo Môi Trường FrozenLake
|
1 2 3 4 5 6 7 |
# Khởi tạo môi trường FrozenLake env = gym.make("FrozenLake-v1", is_slippery=False) env.reset() # Hiển thị số lượng trạng thái và hành động print(f"Số lượng trạng thái: {env.observation_space.n}") print(f"Số lượng hành động: {env.action_space.n}") |
Môi trường FrozenLake:
- Goal: Di chuyển từ ô START đến ô GOAL mà không bị rơi xuống hồ băng.
- Trạng thái (State): 16 ô vuông (4×4).
- Hành động (Actions): Đi lên, xuống, trái, phải (4 hướng).
4.4. Xây Dựng Mô Hình Q-Learning
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
# Khởi tạo bảng Q-table q_table = np.zeros((env.observation_space.n, env.action_space.n)) # Tham số của thuật toán alpha = 0.1 # Tốc độ học gamma = 0.99 # Hệ số chiết khấu epsilon = 1.0 # Hệ số thăm dò epsilon_min = 0.01 epsilon_decay = 0.995 # Số lần chơi num_episodes = 1000 max_steps = 100 # Q-Learning for episode in range(num_episodes): state = env.reset()[0] # Reset môi trường done = False for _ in range(max_steps): # Chọn hành động (Epsilon-Greedy) if np.random.rand() < epsilon: action = env.action_space.sample() # Chọn ngẫu nhiên (Exploration) else: action = np.argmax(q_table[state]) # Chọn hành động tốt nhất (Exploitation) # Thực hiện hành động next_state, reward, done, _, _ = env.step(action) # Cập nhật Q-value q_table[state, action] = q_table[state, action] + alpha * (reward + gamma * np.max(q_table[next_state]) - q_table[state, action]) # Chuyển sang trạng thái tiếp theo state = next_state # Nếu đạt GOAL, kết thúc tập chơi if done: break # Giảm dần epsilon để giảm thăm dò theo thời gian epsilon = max(epsilon_min, epsilon * epsilon_decay) print("Huấn luyện hoàn tất!") |
Giải thích:
- Q-Table: Ma trận Số trạng thái × Số hành động để lưu trữ điểm thưởng.
- Epsilon-Greedy: Ban đầu AI thử nhiều hành động ngẫu nhiên, sau đó tối ưu dần.
- Gamma: Hệ số chiết khấu để ưu tiên phần thưởng dài hạn.
4.5. Kiểm Tra Mô Hình Đã Học Được
|
1 2 3 4 5 6 7 8 9 10 11 |
state = env.reset()[0] env.render() for _ in range(10): action = np.argmax(q_table[state]) # Chọn hành động tối ưu next_state, reward, done, _, _ = env.step(action) env.render() state = next_state if done: break |
Nếu AI đã học tốt, nó sẽ tìm được đường đến GOAL mà không rơi xuống hồ băng.
5. Ưu Nhược Điểm Của Reinforcement Learning
| Ưu điểm | Nhược điểm |
| Học được từ trải nghiệm, không cần dữ liệu nhãn | Cần nhiều tài nguyên tính toán |
| Ứng dụng rộng trong AI chơi game, robot, tài chính | Mất nhiều thời gian để tìm chính sách tốt nhất |
| Có thể tự tối ưu hóa chiến lược hành động | Khó huấn luyện nếu môi trường phức tạp |
Cách khắc phục nhược điểm:
- Dùng Deep Q-Learning (DQN) để thay thế bảng Q-Table.
- Sử dụng học chuyển giao (Transfer Learning) để rút ngắn thời gian huấn luyện.
6. So Sánh Reinforcement Learning Với Các Phương Pháp Khác
| Thuật toán | Khi nào sử dụng? |
| Supervised Learning | Khi có dữ liệu nhãn sẵn và muốn dự đoán |
| Unsupervised Learning | Khi muốn tìm hiểu cấu trúc dữ liệu mà không có nhãn |
| Reinforcement Learning | Khi AI cần tự học cách ra quyết định thông qua trải nghiệm |
Nếu cần AI tự đưa ra quyết định tối ưu theo thời gian, hãy dùng Reinforcement Learning!
7. Kết luận
- Reinforcement Learning là một trong những hướng phát triển quan trọng của AI, giúp máy có thể tự học thông qua thử nghiệm và tương tác với môi trường.
- Bạn có thể mở rộng mô hình bằng Deep Q-Network (DQN) để chơi game hoặc tối ưu hóa quyết định trong robot tự động!